AI*-ul e furt
Să încep cu explicarea asteriscului din titlu, pentru că ăsta e foarte important. AI-ul, așa cum e definit în ziua de azi, nu are foarte multe de-a face cu inteligența artificială, ci este un MLM (Model Lingvistic Masiv) pe care o să îl numim LLM pentru a evita confuzia cu o altă țeapă numită Multi-Level Marketing. Ce e un LLM? Un LLM este un predictor de text - având anumite cuvinte deja, îți prezice care e următorul cuvânt pe care să-l pună. Desigur, e mult mai complex de-atât, dar predicția e de natură statistică. Un LLM nu îți poate formula nimic adevărat, ci doar chestiuni statistic-corecte.
Forță brută
Cum ajung aceste modele lingvistice să îți spună care e următorul cuvânt dintr-o frază? Pentru a face lucrul acesta se aplică un procedeu numit „antrenament” - unui program i se pune foarte mult text în față și începe să genereze text similar. Dacă vede mult Lorem ipsum dolor sit amet în textele respective, de cum scrii „lorem” o să îți zică „ipsum dolor sit amet”, chiar dacă tu ai fi vrut să „lorem nonipsum color sit amet”. Nu există creație, nu există inteligență, nu există personalitate în spatele răspunsurilor pe care le generează LLM-ul; tot ce există este imprecizie statistică (pentru că se folosesc factori aleatori care pot genera răspunsuri diferite). Tot ce contează, așadar, e cât de mare e baza de antrenament a modelului lingvistic - în felul acesta predicțiile LLM-urilor sunt mai aproape de realitate și conversațiile sunt mai credibile.
Motivul pentru care avem discuția de azi e metoda aplicată pentru antrenamentul acestui AI: s-a aplicat metoda pe care niciun profesor de informatică sau matematică nu o recomandă, așa numitul refugiu al incompetenței: aplicarea de forță brută. Modelele astea lingvistice au fost antrenate cu cantități inimaginabil de mari de date în o sumedenie de limbi. Rezultatele sunt într-adevăr de natură să uimească. Oamenii pot avea conversații foarte complexe cu modelele noi de ChatGPT, ai oameni care vorbesc numai despre asta, ai firme care concediază procente serioase din angajați pentru că se bazează pe astfel de unelte (2024: Google, 30.000 dați afară și mai urmează). Există consecințe, așadar; pseudo-AI-ul modern produce victime reale. În fine, nu asta e ideea importantă, ci faptul că pentru antrenamentul AI-ului nu s-a folosit o bază de cunoștințe - nu s-au construit raționamente logice, ci s-a pus în față o tonă de informație și AI-ul îți repetă mai mult sau mai puțin mot-a-mot ce a mai văzut în altă parte pe internet.
De unde vine informația de antrenament
Teoretic, există niște surse publice și există niște surse private. OpenAI e foarte închisă când e vorba despre… erm, cam orice, OpenAI este cea mai bună exemplificare a preluării unui concept și bastardizării lui (conceptul de „Open” în cazul ăsta). Singurul lucru la care e deschis OpenAI e la furt, după cum o demonstrează și New York Times în pregătirea procesului intentat contra OpenAI și Microsoft.
Teoretic, există ceea ce se numește CommonCrawl - cineva care a cotrobăit prin tot internetul și a supt ce informație a putut. CommonCrawl e o organizație non-profit, care strânge datele astea pentru cercetători; e foarte util efortul pentru diverse teme de cercetare. Și cât timp vorbim despre teme de cercetare, sigur, e foarte bine că există această organizație, că e sprijinită de BigTech și pusă la dispoziția oricui (chiar și tu poți descărca sau utiliza parte din acel CommonCrawl, deși bănuiesc că nu prea ai niște petabytes disponibili să-ți descarci local).
Doar că conținutul acela nu e neapărat legal. E plin de informație public-accesibilă care este protejată de drepturile de autor. Care nu ar avea voie să fie accesată public, informație obținută ilicit și pusă public împotriva drepturilor autorilor, sau exploatate într-un fel în care autorii nu sunt de acord. În plus, nu toată informația public-accesibilă poate fi folosită pentru orice scop; de exemplu eu pot să citesc un articol din New York Times sau Times New Roman, să-l dau mai departe cu link spre site-ul autorilor, dar dacă iau articolul cu japca și îl pun la mine pe site deja am încălcat drepturile de autor. La fel cum acest articol este protejat de drepturile de autor - îl poți citi la liber, dar asta nu înseamnă că ai dreptul să-l iei și să-l pui la tine pe site - asta zice bara aia de jos de tot de la finalul articolului. Eu vreau ca tu să poți citi acest text sau orice de pe acest site fără să plătești în plus față de ce plătești pentru a primi acces la internet. Nu vreau să plătești în plus direct sau indirect, prin expunerea la reclame.
Dar chiar și-așa, și conținutul acestui site a fost folosit pentru antrenarea motorului OpenAI, iar autorul, adică eu, nu e notificat în niciun fel când informația de-aici este folosită pentru un scop comercial, nici nu este plătit pentru contribuția lui la sporirea averii acționarilor OpenAI. În fine, mai nou ne-a spus OpenAI că dacă facem o incantație magică nu ne mai folosește conținutul, și o să ne facem că-i credem. Dar OpenAI nu folosește numai ce e accesibil la liber pe internet, ci și o sumedenie de conținut protejat de drepturile de autor la care teoretic n-ar trebui să aibă acces public. Chiar oamenii de la OpenAI au confirmat lucrul ăsta, ei insistând că folosirea materialelor protejate de drepturile de autor (adică mai toate) este fair use.
OpenAI nu sunt singurii care fac lucrul ăsta. Ei sunt cei mai expuși pentru că ChatGPT este produsul de succes care a devenit etalonul pentru LLM-uri.
Furtul secolului
Există o sumedenie de candidați la titlul de „furtul secolului” - întotdeauna există câte-un furt de miliarde de dolari pe undeva. Dar de departe ce fac acum firmele care produc LLM-uri este mai mult decât orice alt furt imaginabil. Atât de mare a devenit furtul cu LLM-uri că mă aștept ca în curând să intervină statele (american, europene, etc.) să legalizeze acest furt - cu cât un furt e mai mare cu atât șansa ca acesta să devină literă de lege este mai mare, pentru că devine o problemă de siguranță națională și stabilitate socială. Ce face OpenAI acum este să devină suficient de mare încât să devină imun la legi - iar procesul cu New York Times este singurul lucru care îi mai poate opri.
Dar, veți zice, poate există vreo modalitate de a construi etic un astfel de model lingvistic masiv? Altul decât ceea ce fac sistemele de educație, care educă modele lingvistice masive de câteva sute de ani, prin școli, licee și universități? Eu suspectez că nu e posibil așa ceva, pentru că orice date ai folosi e imposibil să certifici proveniența datelor. Este textul ăla de pe Wikipedia sau e copy-paste dintr-o carte publicată acum doi ani pentru care autorul vrea să fie plătit? Ar putea fi ambele lucruri! Datele pe care chiar poți să le certifici că sunt din surse acceptabile sunt puține, și verificarea și clasificarea datelor respective în mod corect e imposibilă - trebuie să ceri acordul câtorva milioane de oameni, să faci plăți compensatorii, și tot așa. Nu există nimic gratuit, mai ales nimic gratuit în capitalism.
Bine, capitalismul e parte-complice din acest furt. Până la urmă sistemul capitalist suferă de late-stage-ism, în care vrea să ajungă în forma lui finală în care toate resursele sunt controlate de o elită restrânsă atotputernică. Și toată lumea e complice - de la investitori la utilizatori (care folosesc produse furate pentru a elimina și mai mult nevoia de a răsplăti pe cei din jurul lor pentru eforturile depuse în slujba societății). Utilizatorii sunt complici în această treabă, în fond ei sunt cei care îi dau bani lui OpenAI, să facă mai departe treaba pe care o face, nu?
În fine, ce mi se pare mai interesant e că concurența a dispărut complet. De exemplu, e imposibil să găsești pe google referințe către celebrele faze în care Midjourney creează pe prompturi cu „golden robot” imagini cu C3PO. O simplă căutare după „midjourney golden robot c3po content theft” o să îți dea fix două înregistrări. Din una lipsește cuvântul „furt”, din cealaltă lipsește cuvântul „midjourney”. Hmmm. Oare chiar nimeni nu a scris despre asta? (aș da alt link ironic, dar nu-l mai găsesc pentru că nu l-am salvat la timp și acum Google îl face imposibil de găsit)
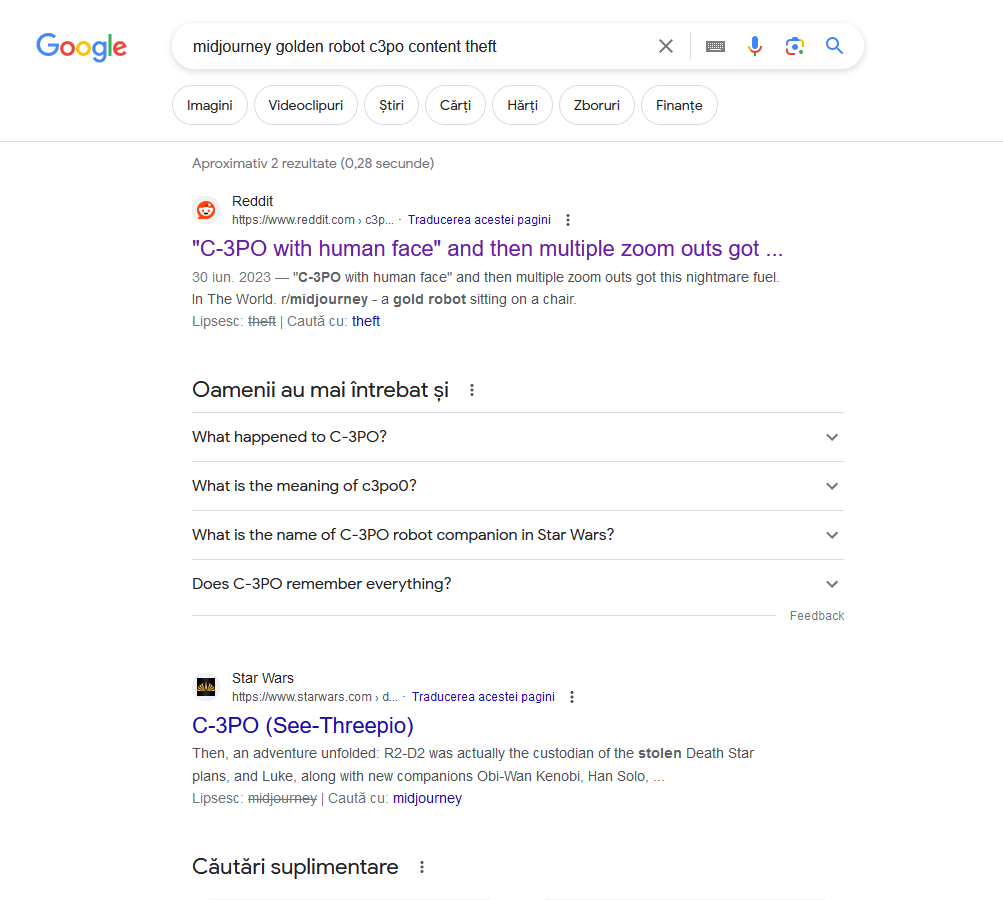
Google ascunde furtul
Altfel nu se poate?
Unul din argumentele producătorilor de LLM-uri este că în cele din urmă, după antrenament, ceea ce au ei este o rețea neuronală pe care o folosesc pentru a-și genera textele-răspuns la interogări. Că în spatele lui ChatGPT nu mai stau informațiile de antrenament, ci rețeaua neuronală antrenată cu datele respective. La fel și cu MidJourney - nu mai stau milioanele de poze/picturi scanate, ci o rețea neuronală care știe ea că un robot auriu este C3PO tot timpul. Nu o să intru foarte mult în argumentarea asta tehnică, dar tot ce vreau să spun e că această rețea neuronală nu le aparține celor care o exploatează, ci celor care au creat informațiile de antrenament. Pentru că dacă acea rețea neuronală ar aparține celor de la OpenAI, Microsoft (o să pun semnul egal între OpenAI și Microsoft, pentru conveniență), Facebook, Google, Amazon, Apple, sau orice alt tâlhar modern, ar fi capabili să spună care e funcția fiecăruia din miliardele de neuroni din acea rețea neuronală (176 miliarde pentru ChatGPT). Argumentul e destul de simplu: așa cu Microsoft este capabilă să explice proveniența fiecărei linii de cod din codul sursă de la Microsoft Office, ar trebui să fie capabilă să explice proveniența și funcția fiecărui neuron din rețeaua ChatGPT, nu? (considerând că OpenAI e Microsoft, etc. etc. etc.)
Ideea e că firmele astea nu sunt capabile să explice funcțiile acelor componente pe care le folosesc, și cât timp sunt incapabile să explice funcțiile lor și să dovedească că într-adevăr le aparțin acele componente nu ar trebui să li se ofere dreptul să le exploateze. În același fel în care în mâncare nu e permisă o substanță necunoscută „pe care am găsit-o noi, așa, aiurea”, nici în computing nu ar trebui să fie permisă utilizarea componentelor cu funcționalitate necunoscută.
Îmi e teamă, însă, că e furtul acesta e de nescăpat. Dacă acum doi-trei ani era imposibil să nu dai peste cineva care vroia să blockchain pentru că, e imposibil acum să mai vorbești cu cineva care să nu vrea să AI pentru că. LLM-ul este o soluție proastă pentru orice pentru că corectitudinea rezultatelor LLM-ului are o valoare statistică. Ceea ce înseamnă că aceeași operațiune repetată de 100 de ori va eșua de 5-10 sau 50 de ori. Nu ai de unde să știi - și nu ai de unde să știi pentru că rezultatele nu sunt predictibile și sunt foarte greu reproductibile. Poate azi LLM-ul îți explică cum să acordezi o ceatârnă sau câte minute să prăjești răbdările ca să fie bine pătrunse, dar mâine se va răzgândi în legătură cu asta.
Lucrurile pot fi făcute altfel - într-o lume ideală m-aș aștepta să văd cercetare în neuro-informatică, o nouă ramură care va face design de soluții pe bază de neuroni în loc de circuite logice. Nu o să vedem așa ceva, din păcate, nu prea curând, pentru că banul primează, și deocamdată nu ai nevoie să înțelegi ce faci cât timp te pui să furi tot ce apuci și să folosești pentru a crea niște chestii pe care nu le-nțelegi dar pe care le poți exploata pentru bani.
Pentru că bani, bani, bani.
BAAAAAAAAAAAAAAAAAAANI.
Bani.